

We don’t want bugs in our code, period. Bugs are not only annoying, they can cost us millions of dollars if they go unnoticed. No matter how hard we try, every time we remove a bug, another pops up in a seemingly unrelated part of the code base.

That is why we do tests: to make sure that the program works as expected when we type something in or interact in any other way. We have tests for everything: unit tests, property tests, visual tests, end-to-end tests, integration tests, smoke tests, stress/load testing, manual testing…
We even do regression testing which checks whether our code updates broke the functionality that already worked in the past! In other words, we have learned to live with tests: we put little green badges in our repositories saying “100% test coverage” so that we can sleep peacefully, knowing that every part of our code was properly tested.
We might sleep peacefully until we come across the following quote:
“… As we know, there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns - the ones we don’t know we don’t know.” — Donald Rumsfeld [1]
To put this in perspective, we know there are some bugs we need to fix (known knowns). We would also expect that if we handle a new feature in an ad hoc manner, it might later come to bite us (known unknowns). The worst kind of bugs, however, are those that we are not expecting (an unknown unknown), i.e., the core functionality we thought was bullet-proof and then tragically fails. In other words, when there’s an error in the functionality that has been thoroughly tested.
Rumsfeld’s thesis has also been extended with the fourth category [2], the unknown knowns: the suppositions we pretend not to know. There is an elephant in the room: tests are great only for catching bugs that we would expect. After all, we are testing only what we know might fail and only on inputs we assume to be critical. For other kinds of inputs, we assume they are handled automatically, whereas in reality, that is far from guaranteed. Much harm can be done if we fail to acknowledge this.
Despite all the tragedies, we have learned to live with the idea that for most applications, tests and Q&A are enough. One can argue that tests have worked quite well for us and that the world cannot be perfect. Let us make a simple comparison, then. Would you walk on a bridge built of a new rock solid material, knowing that no external auditing or inspection was done, but a group of 20 vehicles rode on every square foot of its surface? The bridge was indeed “100% tested” for its use case. We only want it to stand still for passing vehicles. What happens when we get an unexpected input such as resonance? Well-written tests are great, but something that we forget to test might always crop up.
When Tests Fail
We are software engineers, so let us finally talk about engineering software and not bridges. All around us there’s software that powers critical systems. Sometimes we don’t even realize it. Mere fetching data from a user table can cause a leak that could make a company bankrupt. Not to mention smart contracts, which are nothing but programs that are executed if some predefined criteria are met. Mistakes can have severe consequences. We should always be writing code as if for our local nuclear power plant.

{kind=link}
Imagine you actually are implementing a function for a nuclear power plant. There are n cooling towers that pump heat out of the reactor’s proximity. Your task is to program the logic which controls the cooling mechanism. Let us consider a simplified, hypothetical (and slightly distorted) scenario. The logic only controls how much water goes in based on the reactor’s temperature and decides how it is distributed among the towers. If there is too much water in the pipes, the reactor is too cold. The systems will not run efficiently, leading to waste. This may cause the towers to age poorly, and in the worst case, the pipes can break. If there is too little water in the pipes, well, we do not need to explain that part (the reactor melts).
Bear in mind that the reactor is a living organism, the situation changes every nanosecond. You cannot just type “allow this constant amount of water to pass”. What is more, there are several towers and only one reactor. That means you do not want one of the n towers to become overwhelmed and the rest remain idle.
How do we approach this? Well, we want to balance the temperature around some value and distribute the water among the towers as much evenly as possible, right? The first idea that comes to mind is a simple “linear balancer”. Say we calculate a water constant saying how much water we need per 1 degree. If the temperature changes by 1 degree, we simply add/remove the corresponding amount of water. With a little bit of foresight, we also realize that we cannot push a negative amount of water, so we also enforce that with the min function:
function getWaterAmount(int last_temperature, int temperature, int last_amount): [int] {
int amount = min(0, last_amount + (temperature - last_temperature) * WATER_CONSTANT);
return [amount / n, …, amount / n];
}Now we want to make sure this intuition works. Since it’s a power plant, we’ll allow that we use something more advanced such as fuzzing. Fuzzing is an automatic testing technique that chooses a set of inputs according to some predefined model. The model tries to find unexpected inputs that crash our program. We’ll try to use fuzzing to test the cooling mechanism we’ve just implemented.
Let’s assume that we have a magic function getAverageTemperature([int] water), which correctly tells us what the reactor’s average temperature will be based on the amount of water. We’d like to test the straightforward property saying that the temperature won’t jump over either of the extremes by fuzzing the reactor state:
function test_temperature(): bool {
int temp = getAverageTemperature(
getWaterAmount(fuzz_last_temp, fuzz_temp, min(fuzz_last_amount, 0))
);
return LOW <= temp <= HIGH;
}After we run the test (starting in a balanced state), let’s say everything checks out and passes the above fuzz test. The question for the audience: is getWaterAmount bug-free? Would you feel safe knowing that your local power plant uses this function even after there are 20 other passing tests of it? Or 1000 high-quality tests? How many tests are enough? We are not testing just some random function. I guess one is starting to see that an easy problem turned into a complicated beast. And somehow the solution might seem too good to be true. After all, the average temperature stays normal… If you do not see any problems here, among the many questions you should be asking yourself:
Need for Formal Verification
One of the biggest challenges in writing good tests is that we do not know which inputs are important. We might overlook some very weird combinations of inputs. Fuzzing improves our chances in this respect because it can be effective in a systematic combing through the input space, but we are still the ones who somehow influence the finite choice of inputs.
What if instead of deciding which cases to cover, we could cover all cases at once? This is the idea behind program verification, which applies formal verification techniques on verifying correctness of programs. We specify exactly what it means for a program to be correct in advance, and then (algorithmically) verify that the program behaves on all inputs according to our specification. If we have a very good idea of what it means for our program to be 100% correct and the specification mirrors this faithfully, then (in theory) program verification can confirm that the program is 100% correct. This is because we are able to exercise our specification on all inputs and because the specification must hold everywhere we require it. This is different from testing: 100% test coverage can mean that we tested 1% of the inputs and some parts of the code base were tested on 0.00001% of the inputs.
The problem of writing good tests is thus reduced to the problem of writing good specifications. Are we jumping out of the frying pan to the fire? Not necessarily. In the following paragraphs, we will very briefly explain why.
Functional Correctness
Let us quickly recall basic terms from our Algorithms class. When analyzing algorithms, one usually specifies a precondition and a postcondition. A precondition is a formal statement saying for what inputs the algorithm should work – it is simply a list of assumptions about our input. A postcondition is a formal statement saying what conditions the output should satisfy.
We say that the algorithm is partially correct if a (potential) output satisfies the postcondition for any input satisfying the precondition. The algorithm is called correct if it is partially correct, and is guaranteed to halt. Now replace the term algorithm in all definitions with the word program. Voila, we get a very faint grasp of what it means that a program is correct. Faint because programs can be more complicated and that is why we need something more general than this.
Specifications
Specifications could be seen as a generalization of pre- and post-conditions. They are usually given in some specification language or logic and tell how a program should behave. Compared to tests, they can also be viewed as properties which have to be property-tested on all (usually infinitely many) inputs in order to be true.
As one can imagine, it is sometimes very hard to specify what we actually want. For example, what is the correct behavior of an operating system? That is why one of the most popular kinds of specifications are reachability claims. These are in essence always the same. We are interested in whether a program can reach a set of (error) states. Inputs for reachability conditions are usually program runs. In the case of the nuclear reactor software, we could specify something along these lines:
No run of the reactor software reaches the function setOffMeltdownAlarm().
This is the idea of reachability logic, which enables us to easily prove claims of this kind given a set of assumptions. Of course, we need to trust that the compiler and the verifier are correct. In embedded systems, we also have to trust that the physical device abides by its (software) model. This is ok: we are verifying the correctness of reactor software, not the reactor (interface) itself.
We can also specify much more complex conditions. For example, in matching logic and the K framework, a program run is usually represented in terms of a sequence of states. A state is just a collection of data structures such as the function stack holding what function we are in and how we got there. Then we can specify reachability conditions with respect to program states, which gives us the expressiveness we need.
Writing specifications is a tedious process, but there are experts in this area. If you would like to come up with a set of specifications for your software, the easiest way to start is by contacting a verification engineer that will walk you through the entire process on-site. Let us assume now we have a good specification. Next, we want to verify that it holds, i.e., that our program behaves as specified, which is going to be covered next.
Verification
A program verifier takes the program and specification as input, and ideally decides whether the program meets its specification. There are many techniques to achieve this and it is an active area of research. For example, in deductive verification, the system is modeled as a logical theory and the specification is a logical theorem to be proven. Proof obligations can be discharged in proof assistants, automatic tools such as SMT solvers, or a combination of both (where the user needs to fill in details when an automatic tool is stuck). Specifications can also be written as annotations, and some languages even require it for programs to compile successfully.
The K framework we’ve discussed generates a (semi-automatic) deductive verifier for proving reachability claims. Its main advantage over other verifiers is that it forces the interpreter and the verifier to use the same semantics of the target programming language. In simple terms, there is no translation to an intermediate model. The semantics of a language are a logical theory that you plug in. The K verifier works with the same machine code as the interpreter, and that is why it isn’t possible to get two different behaviors of the same program dependent on whether we use the interpreter or the verifier. This is a unique feature of the K framework: other verification methods usually rely on some intermediate or ad hoc representation of the program, which leaves room for error. For example, Grigore Rosu presented the following simple program:
Even though the return value of main is in this case undefined according to the C standard, gcc4 returns 4, gcc3 returns 3, and some formal verifiers “prove” it is still 4! This is unacceptable in formal verification, which should give you absolute guarantees regardless of the used compiler. We are starting to see that verifiers should be based directly on the specification of programming languages: its formal semantics.
We can extend this principle even further. If both our compiler and verifier rely upon the same reference, formal semantics, then program runs and proofs of reachability claims are the same thing. When we want to claim that a program can reach some state, we provide a valid program run ending in this state as proof, which shows exactly how it can happen. The K verifier simply runs symbolic execution on a given program and tries to find such a run. If it successfully finds a run like this, then it confirms the reachability claim. If it does not find a run like this, it can reject the claim because symbolic execution examines all runs using symbolic inputs. The following snippet shows how bug1() cannot be reached by any run because the path condition about n is infeasible:
function foo(int n) {
// n : int
if (n > 0) { // n : int && n > 0
if (n <= 0) { // n : int && n > 0 && n <= 0
bug1();
}
}
}This simple example would probably also be caught by a linter, but symbolic execution can handle much more complicated cases. Symbolic inputs cover the entire input space of concrete inputs. This is a huge advantage over testing, which only works with a finite number of concrete inputs. A passed test of some property does not mean that the property holds for all inputs, only for the tested inputs. When a test does not find any evidence of an error, we cannot claim that the program is bug-free. With verification, we can.
The main takeaway from the K framework is that we do not need any intermediate representation of the program or the claim, we can work directly with the underlying code. When relying on other methods, correctness often depends on whether the representation of the program and the claim really correspond to the original! For each programming language, the translation can be different and complicated. In the K framework, we take the program as is, run it as is, and verify as is. Proofs are not abstract but very concrete because each tool for our language uses the same reference, its formal semantics written in the K language:
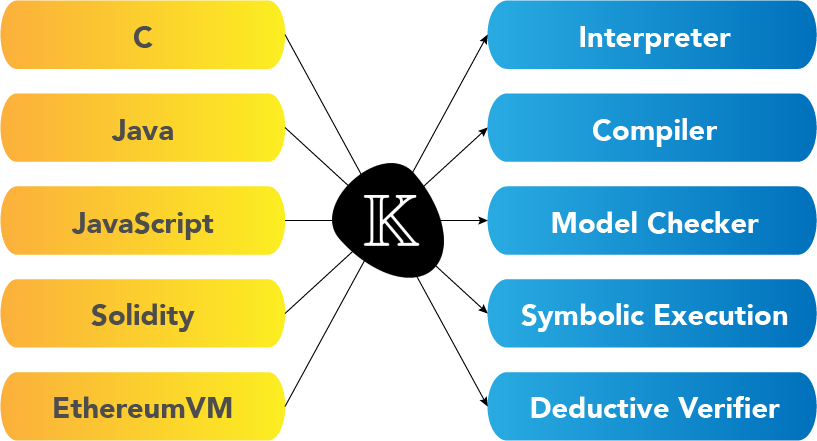
One can argue that we may write an insufficient specification in the same way as we may write an insufficient test suite. Yes and no. Verification is, in a way, a generalization of testing, not an opposing technology. In an ideal world, we could only have specifications, which would also cover what we usually cover with tests. We would do specification-driven development: we would write specifications first to make sure we really understand what we want to do, and only then would we implement it.
However, verification and specification can be a time consuming process that usually takes more time than testing. The best option in critical systems is to run verification on top of testing. There is nothing preventing you from including verification in your Q&A process. This can only have advantages: you do not have to throw away your tests and trust verification completely, you can have it as an extra layer of examination. Together with audits, which we are going to discuss next, this gives the best guarantees we can currently have in software.
Audits
We are experts on code, not necessarily on the domain of our application. We should fight our every assumption as hard as we can, and when we are even slightly uncertain, we should consult an independent party. A power plant engineer would probably be horrified reading through the getWaterAmount example. There are red flags everywhere:
- How did you come up with that water constant?!
- Can you really make decisions based on local state only
snippet?! - Are you sure you want to use a linear function on an exponentially behaving system?!
- You really want to test against an average temperature metric?! That is insane!
- What happens when you want to pump more water than available?!
- What happens when there is a memory overflow?!
- How did you come to the conclusion that the water should be evenly distributed?!
- How do you schedule the entire thing? There is a whole branch of computer science devoted to the analysis of real time systems. Timing is a huge source of bugs even in single processor scheduling.
The list can go on and on. Sometimes we are so engulfed in our own solution that we start to overlook why it is wrong. We don’t have to write code for a power plant here. What if we have, for example, a financial product and we want to scale? Do we really not want to use any technique available to make sure we can? The best way to avoid self-deceit is to have an independent audit of our code.
External code reviews
Why do we need someone external to look at our private code and pay them to do it? We have our own security specialists… We can hire more of them if needed. The answer is that auditors are not there to replace a security team, but to supplement it. External auditors can assess risks independently without any peer pressure. Moreover, auditors have regular experience from multiple projects. That way they might spot something the security team is used to seeing even if it might be problematic.
If your audit firm is doing white-paper reporting, then you know you made the right choice. It means that problematic parts and bugs are discussed with your team on a regular basis. This is how it is supposed to be done: audit firms are selling services, not reports. Auditors also cannot do their work properly if they have no feedback from the developers. The better a codebase is devised, the deeper auditors can actually investigate. How does it work?
- The auditing team discusses with you the time plan and ideas about what needs to be checked.
- You provide secure access to your repository.
- The auditing team researches all your relevant materials and studies your code.
- The auditing team creates an abstract model of your codebase and analyzes it.
- The auditors refer to a database of known security flaws and check that your code does not suffer from any of them.
- A report is written explaining all the findings and possible solutions. You can usually choose what goes public and what response you want to include. An example report can be found here.
If you’re still not convinced, there is a simple analogy. Imagine scientific papers are not peer-reviewed, only double-checked by the research team members. Would you trust the results as much as if they were published in a top journal that verifies every claim an author makes? External companies auditing your code give you another level of guarantees and trust. That is something you cannot achieve with your team alone.
Conclusion
Tests are great if we know exactly what to test. Unfortunately, this is usually not the case. There’s a huge chance we are overlooking something, and because tests cover only a finite set of inputs, the scope of bugs can be much greater than we expect. There are two things we can do immediately to improve code reliability and safety. One option has been realized by engineers (and scientists) since their early beginnings: external audits (and peer review). The second is a technique that is finally starting to be feasible in large-scale programs: verification. Verification techniques are the topic of ongoing research, but we can use some of them today.
There’s one takeaway that can never be emphasized too much: we should be cautious when writing our code, because poor design choices can “explode” in the future. Ideally, we specify first what we are actually about to program, and only then start working on the implementation. This is the simple idea behind specification-driven development: we are writing programs and proofs of their correctness at the same time. The question that remains is, how do we write good specifications? What should we look out for? How can we be sure that our specification is sufficient and why is operational semantics important? We are going to look at this in the follow-up article.
References
[1] RUMSFELD, Donald. “Defense.gov News Transcript: DoD News Briefing – Secretary Rumsfeld and Gen. Myers, United States Department of Defense (defense.gov)”. February 12, 2002. Archived from the original on March 20, 2018.
[2] ZIZEK, Slavoj. “What Rumsfeld Doesn’t Know That He Knows About Abu Ghraib”. Retrieved February 23, 2009.
Originally published at https://runtimeverification.com on October 12, 2022.